Building an LLM Document Extraction Benchmark Framework
Large Language Models (LLMs) are increasingly being used for structured information extraction from documents such as resumes, invoices, and reports. However, different LLMs behave differently in terms of extraction accuracy, execution time, consistency, and output quality. Choosing the right model for document extraction tasks therefore becomes an important challenge.
To address this, we built an LLM Document Extraction Benchmark System that compares multiple LLMs on structured document extraction tasks. The framework evaluates models using common prompts and documents, then measures their performance using metrics such as execution time, accuracy, precision, recall, and F1 score.
The project supports both local and cloud-based LLMs and provides a benchmarking pipeline for comparing extraction quality, execution time, and structured output consistency across different models.
🎯 Project Goal
The goal of this project is to build a generic LLM Benchmarking Framework for evaluating how effectively different Large Language Models perform structured information extraction from real-world documents.
The framework helps compare models based on:
- Extraction accuracy
- Execution time
- Output consistency
- Structured response quality
The system benchmarks multiple local and cloud-based LLMs using the same documents and prompts to ensure fair and reliable comparison for document extraction workflows.
🧠 Models Evaluated
The project benchmarks both local and cloud-based LLMs.
| Model | Platform |
|---|---|
| Llama3 (8B) | Ollama |
| Mistral (7B) | Ollama |
| Qwen2.5 (7B) | Ollama |
| GPT-4.1 | Azure OpenAI |
| Azure Llama 3.1 | Azure AI |
Each model processes identical prompts and documents, allowing direct comparison of extraction quality and execution performance.
🏗️ System Architecture
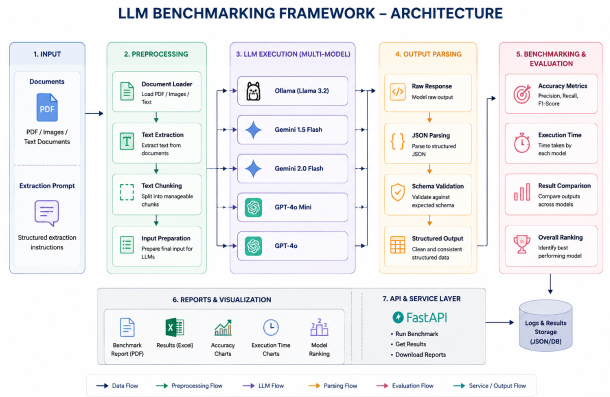
The benchmarking framework was designed so that every model receives the same document, extraction prompt, and evaluation workflow to ensure fair comparison across all models.
The project was implemented using:
- FastAPI for backend API workflows
- Ollama for running local LLMs
- Azure OpenAI APIs for cloud-based model testing
- PyPDF for document text extraction
- Pandas & OpenPyXL for automated benchmark report generation
The pipeline extracts text from documents, sends standardized prompts to multiple LLMs, parses the generated responses into structured JSON outputs, validates the outputs, and compares model performance using metrics such as accuracy, precision, recall, F1 score, execution time, and output consistency.
Each model was executed independently, and execution time was measured separately to compare model latency and extraction performance fairly.
One of the major challenges was handling inconsistent LLM outputs such as invalid JSON, missing fields, and hallucinated values. To solve this, additional parsing, validation, and formatting logic was implemented before evaluation.
⚡ Backend API using FastAPI
The project also includes a FastAPI backend that allows extraction and benchmarking through APIs.
Example Endpoint
from fastapi import FastAPI, UploadFile
app = FastAPI()
@app.post("/extract")
async def extract(file: UploadFile, prompt: str):
return {
"message": "Extraction Started",
"prompt": prompt
}
FastAPI provides:
- High-performance APIs
- Automatic Swagger documentation
- Easy integration with AI workflows
- Scalable backend support
🌐 Swagger UI Support
FastAPI automatically generates interactive API documentation.
http://127.0.0.1:8000/docs
Swagger UI allows direct testing of extraction endpoints from the browser.
Benchmarking
📂 Supported Document Formats
The framework supports multiple document formats:
- TXT
- DOCX
- XLSX
This flexibility makes the system adaptable for different enterprise document workflows.
✨ Prompt-Based Extraction
One of the most important features of the system is prompt-driven extraction. The system automatically identifies requested fields from Resumes and generates structured JSON outputs.
Instead of hardcoding extraction rules, users dynamically define extraction fields using prompts.
Example Prompt
Extract name, email, phone, skills, education, and experience from the document.
The system automatically identifies requested fields and generates structured JSON outputs.
📊 Benchmarking Metrics
The framework evaluates models using:
- Execution Time
- Accuracy
- Precision
- Recall
- F1 Score
This helps identify the best-performing model for real-world extraction systems.
📊 Benchmark Performance Comparison
| Metric | Llama | Mistral | Qwen | GPT-4.1 | Azure-Llama |
|---|---|---|---|---|---|
| Execution Time (sec) | 58.24 | 89.71 | 62.28 | 4.12 | 1.99 |
| Accuracy | 100 | 71.43 | 85.71 | 100 | 85.71 |
| Precision | 100 | 71.43 | 85.71 | 100 | 85.71 |
| Recall | 100 | 100 | 100 | 100 | 100 |
| F1 Score | 100 | 83.33 | 92.31 | 100 | 92.31 |
These comparisons help evaluate model performance based on extraction accuracy, execution speed, response consistency, and overall benchmarking efficiency.
📁 Generated Reports
The framework automatically generates:
Benchmark Output Report
benchmark_output.xlsx
Contains:
- Extracted fields
- Ground truth values
- Predictions from each model
- Execution times
Accuracy Report
benchmark_accuracy.xlsx
Contains:
- Accuracy
- Precision
- Recall
- F1 Score
🧩 Challenges Faced
Building reliable LLM extraction systems comes with several challenges.
1️⃣ Inconsistent Outputs
LLMs may generate:
- Invalid JSON
- Missing fields
- Additional explanations
- Incomplete responses
✅ Solution
- Structured prompts
- Validation layers
- Parsing logic
2️⃣ Hallucination
Sometimes models generate information not present in the document.
✅ Solution
- Better prompt design
- Validation checks
- Controlled output formatting
3️⃣ Parsing Failures
Improperly formatted outputs can break downstream workflows.
✅ Solution
- Exception handling
- Fallback parsing
- JSON validation
🔥 Key Features
- Multi-model LLM benchmarking
- Prompt-driven extraction
- Structured JSON output
- FastAPI backend integration
- Swagger UI support
- Execution time benchmarking
- Automated Excel reports
- Support for multiple document formats
🎯 Conclusion
LLM benchmarking plays an important role in identifying which models perform better for structured document extraction tasks based on factors such as accuracy, execution time, and output consistency.
This project demonstrates how multiple local and cloud-based LLMs can be evaluated using a common benchmarking pipeline with standardized prompts, structured validation, and automated reporting. By integrating FastAPI, prompt-based extraction, validation workflows, and benchmarking metrics, the framework provides a practical and scalable approach for comparing document extraction performance across different models.
The project also highlights that selecting the right LLM depends not only on intelligence, but also on reliability, speed, and consistency for real-world AI workflows.
🔗 GitHub Repository
Check out the complete project here:
https://github.com/admin-suketa/LLM_Document_Extraction_Benchmark
📚 References
-
FastAPI Documentation (2026). Available at: https://fastapi.tiangolo.com/
-
Ollama Documentation (2026). Available at: https://ollama.com/
-
OpenAI API Documentation (2026). Available at: https://platform.openai.com/docs/
-
PyPDF Documentation (2026). Available at: https://pypdf.readthedocs.io/
-
Microsoft Azure OpenAI Documentation (2026). Available at: https://learn.microsoft.com/en-us/azure/ai-services/openai/