From Seconds to Milliseconds - Accelerating Search Hints with SQLite
The Challenge: Building a Search Engine
A few weeks into my internship, I was handed an exciting but daunting project: building a fast, responsive search engine that could handle rapid keystrokes and deliver instant search hints.
The backend stack for this project was built for high throughput and rapid processing:
- Core Server: Node.js and Express.js (handling routing and CORS).
- Data Processing: Multer (for fast in-memory file uploads) and
csv-parser(for efficient stream processing of datasets).
The project was originally architected to use Neo4j as the primary database. Neo4j is a powerful graph database, fantastic for managing highly connected data, complex relationships, and deep analytical queries.
At first glance, relying entirely on Neo4j for everything—including search hints—sounded like a robust plan.
It wasn't.
While the data ingestion and complex relationships were handled beautifully by the graph database, the actual user experience of typing into the search bar was suffering.
That immediately raised two questions in my mind:
- Why was a simple autocomplete query taking so long?
- Was a graph database the right tool for delivering keystroke-level search hints?
Answering those questions turned into an insightful journey into database optimization, network latency, and the true value of portability.
Understanding the Bottleneck: The Cost of API Hits
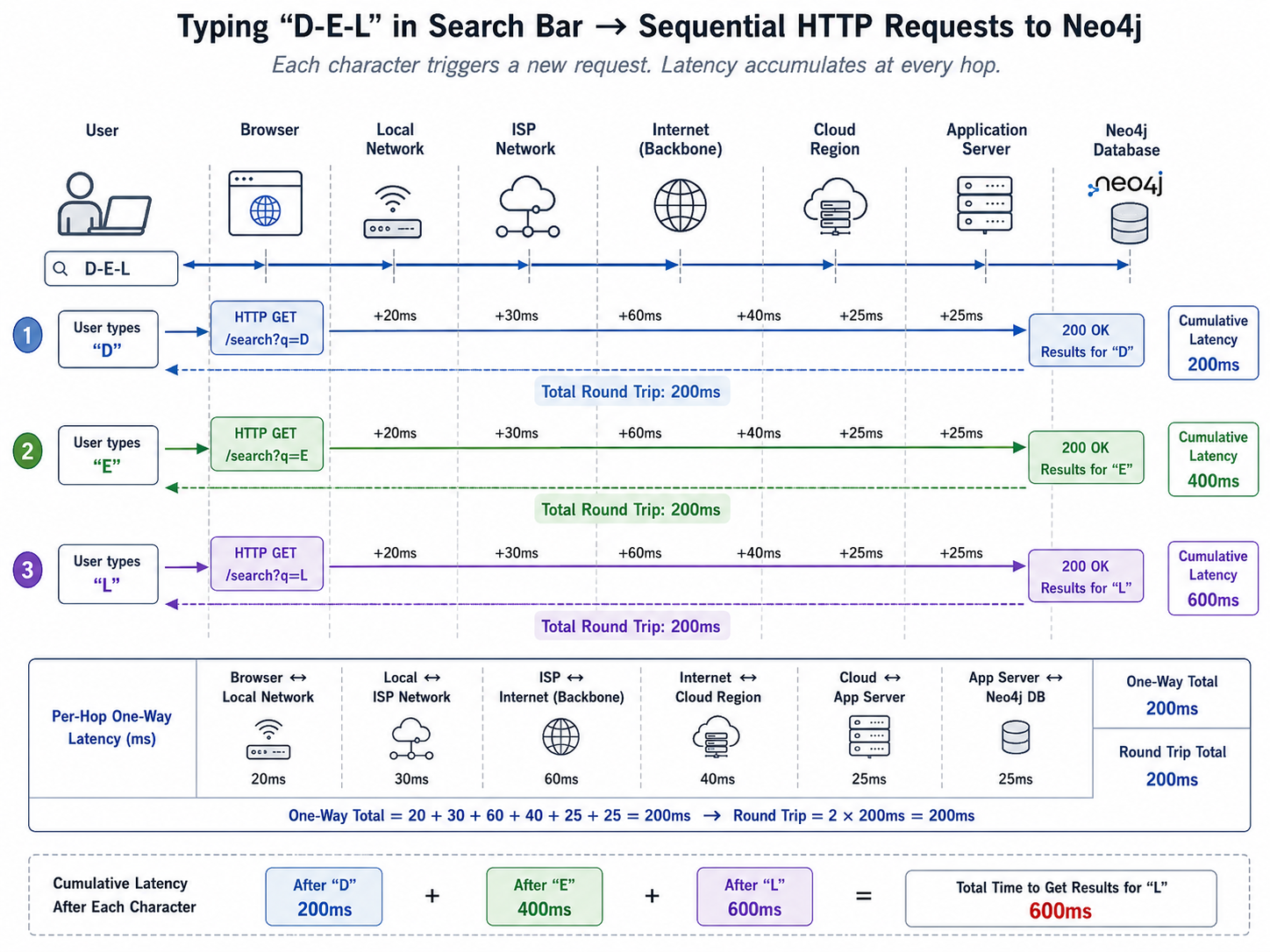
Initially, the search flow was straightforward. When a user typed a letter, an API call was triggered, the backend queried Neo4j, and the results were returned to the client.
The problem was the sheer volume of API hits and the network overhead. Even assuming some debounce mechanism on the client side, a user typing "Delhi" rapidly fires off several queries to our backend. While Neo4j's write performance was absolutely fine for our ingestion needs, querying a remote graph database for every keystroke introduced massive overhead.
The issue wasn't the Neo4j engine itself; it was the network latency, the query parsing overhead, and the fact that we were using a heavy-duty graph engine to do a simple LIKE 'delhi%' prefix match. When hundreds of users are querying simultaneously, those milliseconds add up, resulting in sluggish API response times that break the real-time illusion.
The implication was significant: we couldn't rely on remote database calls for a feature that demands real-time, zero-latency feedback.
Exploring Alternatives: The Need for Speed
I realized that for search hints to feel truly instantaneous, the data needed to live as close to the application as possible. I started looking into embedded databases that run within the application process itself, completely eliminating network round-trips.
I narrowed my focus down to two of the most widely used embedded databases: RocksDB and SQLite.
The Contenders
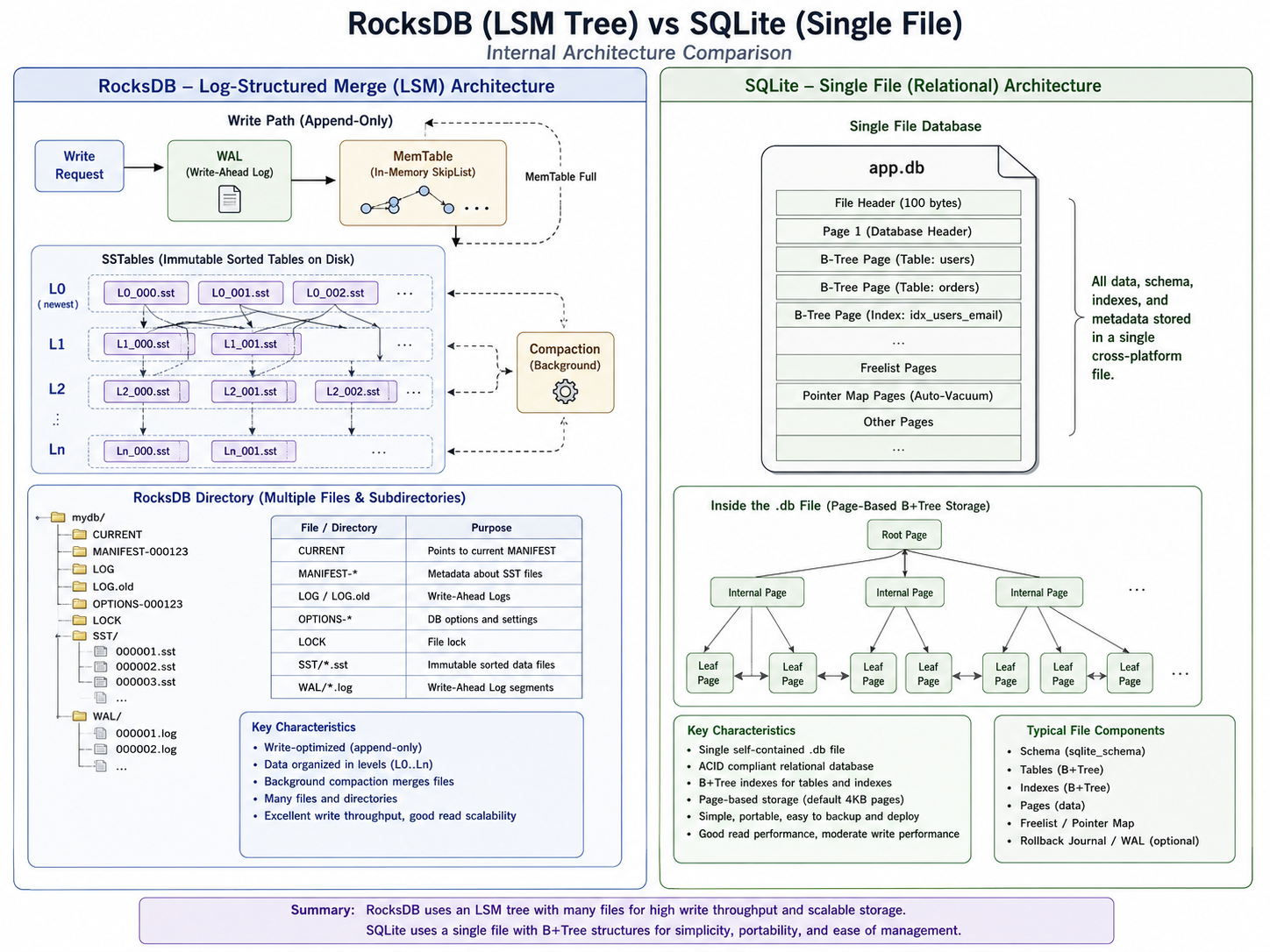
RocksDB (developed by Facebook) is an embedded key-value store optimized for fast storage and high-performance reads/writes. It's incredibly fast but operates purely on key-value pairs, which makes complex relational querying or prefix matching slightly more manual.
SQLite is a C-language library that implements a small, fast, self-contained, high-reliability, full-featured, SQL database engine. Specifically, we looked at integrating it via better-sqlite3, a synchronous Node.js library known for its incredible speed compared to asynchronous alternatives.
Technically, both approaches were capable of solving the speed issue. Practically, one stood out as the clear winner for our specific use case.
The Deciding Factor: Portability
While RocksDB is blazing fast, it stores data as a complex directory of files. Managing it, backing it up, or transferring it to another environment requires moving whole directories and ensuring environment compatibility.
SQLite, on the other hand, offered something magical: Ultimate Portability.
An entire SQLite database is stored as a single, cross-platform file on the disk (search_data.db).
This portability was a game-changer for the project. It meant that:
- Easy Integration: The search database could be generated once and easily transferred or exported to any kind of project.
- Simplified Deployment: No need to configure database servers, manage credentials, or set up background services. You just drop the
.dbfile into the project folder, and it works. - Familiarity: Because it uses standard SQL, any developer on the team could easily inspect, query, and debug the database using tools they already knew.
As engineers, we don't always just optimize for raw speed; we optimize for developer experience and maintainability. SQLite gave us embedded speeds and the flexibility to ship the search engine anywhere.
Bridging the Gap: The Hybrid Pipeline
Rather than completely ripping out Neo4j—which we still needed for deep relational data—I designed a hybrid pipeline to bridge the gap between the two databases.
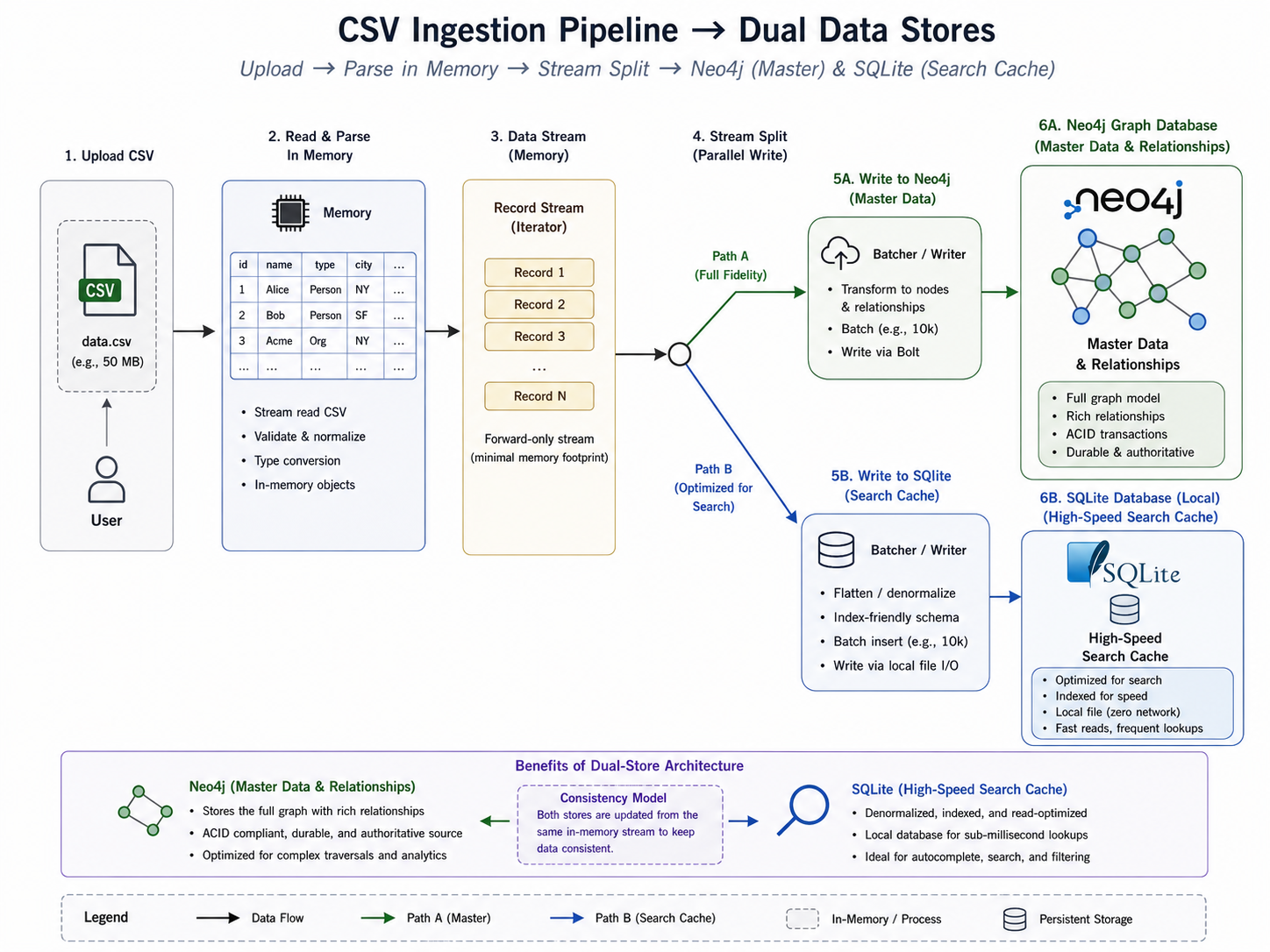
Here is how we architected the solution:
- In-Memory Parsing: When a user uploads a CSV file, Express intercepts it using
multerwithmemoryStorage(). We parse the buffer directly in memory usingcsv-parserto avoid unnecessary disk I/O. - Neo4j Ingestion (The Master): The raw data is batch-inserted into Neo4j as
SearchItemnodes. This serves as our master record and relational backbone. - SQLite Caching (The Speed Layer): Simultaneously, we rebuild the local
search_data.db. We insert the exact same data into an SQLite table with three columns:primary_val,secondary_val, and a specially indexedlower_primarycolumn.
By indexing the lower_primary column, an autocomplete query like SELECT primary, secondary FROM search_data WHERE lower_primary LIKE 'delhi%' executes in roughly 5 milliseconds, compared to the hundreds of milliseconds it took over the network.
Measuring the Impact and Lessons Learned
The outcome of bridging these two databases was immediately noticeable.
- Old Architecture (Neo4j over Network): Hundreds of milliseconds per API query.
- New Architecture (Embedded SQLite): Sub-millisecond database read times.
The search API endpoint went from being a major bottleneck to resolving almost instantly. From an infrastructure perspective, the optimized backend architecture offered the best of both worlds: Neo4j retained its role as the source of truth for relationships, while SQLite delivered the localized, hyper-fast, portable reads required to support real-time APIs.
Looking back, this project reinforced several lessons:
1. The Right Tool for the Right Job
A database that excels at complex graph traversals isn't necessarily the right tool for rapid prefix matching. Splitting workloads across different optimized databases is often the key to high performance.
2. Network Overhead is the Enemy of Real-Time UX
When building features like autocomplete, the network is your biggest bottleneck. Bringing the data closer to the compute layer (via embedded databases) is one of the most effective ways to slash latency.
3. Portability is a Superpower
Speed is essential, but the ability to easily transfer, export, and integrate a solution across multiple projects saves countless engineering hours. A single-file database is incredibly powerful.
In the end, the most impactful change in this project wasn't writing a more complex algorithm. It was understanding the physical limitations of network calls, combining the strengths of two very different databases, and realizing that sometimes, the best solution is a simple file on a disk.